I gave a presentation on Buffon’s Needle Problem in a job interview once. Here’s the presentation I gave in PDF format if you’re interested. If you’ve never heard of Buffon’s Needle Problem, you should open my little presentation and browse through it. It’s one of the damndest things I’ve ever learned.
Here’s the setup. Imagine you have a floor with parallel lines, kind of like hardwood floors, with all lines equally spaced from one another. Let’s say the distance between the lines is L:
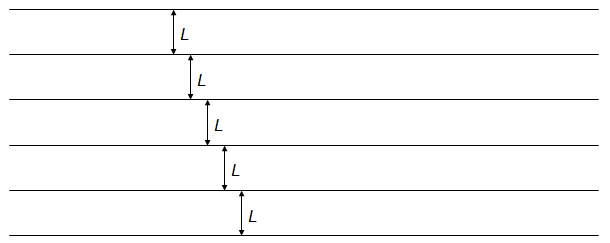
Now imagine you drop some needles of length L on the floor and count the instances of where the needles cross the lines:
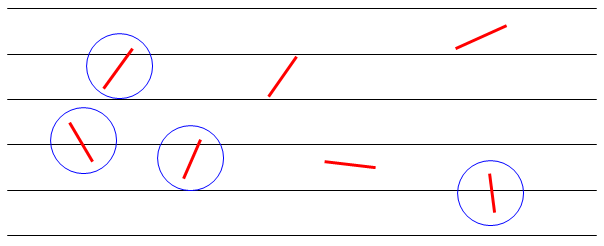
Yes, I know, I have red needles! Cool, right? Anyway, here’s the crazy thing: if you drop a lot of needles (say 10,000) and count the number of needles crossing lines, you can use that information to estimate Pi! It turns out that if the distance between lines and the needle length are both 1, then \( \pi \approx \frac{2n}{k} \), where n = number of needles and k = number of needles crossing lines. I don’t know about you but I think that’s nuts!
Let’s fire up R and see this in action. Here’s slightly modified code from the presentation:
a <- 1 # length of needle
L <- 1 # distance between lines
n <- 100000 # number of dropped needles
hit <- 0
for(i in 1:n) {
x <- runif(1,0,1)
y <- runif(1,0,1)
while(x^2 + y^2 > 1) { # no points outside of unit circle
x <- runif(1,0,1)
y <- runif(1,0,1)
}
theta <- atan(y/x) # the random angle
d <- runif(1,0,(L/2)) # distance of needle midpoint to nearest line
if(d <= (a/2)*sin(theta)) {
hit <- hit + 1
}
}
pi.est <- (n*2)/(hit)
pi.est
First I define the distance between the lines (L) and the needle length (a) to both be 1. They don't have to be equal, but the needle length does need to be less than or equal to the distance between the lines. It turns out that in general \( \pi \approx \frac{2na}{kL}\). In my example, I have \( a = L = 1\), so it simplifies to \( \pi \approx \frac{2n}{k}\). Next I define a variable called "hit" to count the number of needles crossing a line and then I dive into a loop to simulate dropping 100,000 needles.
The first 7 lines in the loop generate a random acute angle (less than 90 degrees or \( \frac{\pi}{2}\) radians) by way of the arctan function and x and y points that lie within the unit circle. The reason the points need to lie within the unit circle is to ensure all angles have an equal chance of being selected. The next line randomly generates a distance (d) from the midpoint of the needle to the nearest line. Using my random angle and random distance I then check to see if my needle crossed the line. If \( d \le \frac{a}{2}sin(\theta)\) then the needle crossed the line and I increment my hit counter. In my presentation I try to justify this mathematical reasoning using pretty pictures.
Finally I calculate my Pi estimate and spit it out. I ran it just now with n = 100,000 and got 3.136517. Not an accurate estimate but pretty close. When I tried it with n = 1,000,000 I got 3.142337. The more needles, the better your estimate.
Now is this practical? Of course not. I can Google Pi and get it to 11 decimal places. R even has a built-in Pi variable (pi). But the fact we can use probability to estimate Pi just never ceases to amaze me. Nice going Buffon!